
Customer Review Sentiment Analysis
The project aims to analyse the sentiment of amazon reviews with the help of Machine Learning & Deep Learning. Sentiment analysis (or opinion mining) uses natural language processing and machine learning to interpret and classify emotions in subjective data. This helps to further understand the overall sentiment of customers as well as predict the sentiments of incoming reviews. Additionally, the models were deployed to Heroku and an application was developed using Flutter to predict sentiment of any input sentence using API calls.
The reviews were collected from the dataset provided by Jianmo Ni available HERE. They were initially cleaned by removing stopwords and lemmatizing each word of the sentence to get the roots. Then, feature extraction was conducted on the collected reviews. Here, two ways to make binary/boolean features or to vectorize were exercised.
- True/False approach:
- In this approach, the presence of certain words (features) in training data is tested and fitted to the resultant sentiment.
- Each feature is given a sentiment probability based on the number of times one classification is made with the presence of each feature being true (is present) or false (is absent).
- Here, it only considers the occurrence of the feature and not the frequency.
- Count Vectorization approach:
- In this approach, the words (features) are converted into a vector (matrix) storing the number of occurrences of each feature i.e. its frequency.
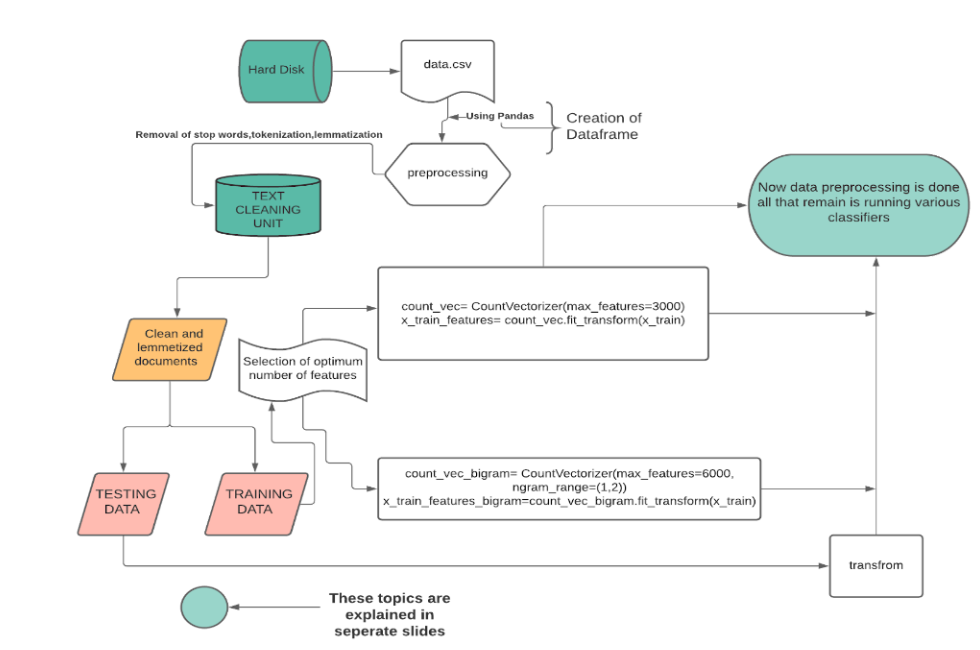
The following classifiers were utilized:
- From NLTK (True/False based):
- Bernoulli Naive Bayes
- From Sklearn (Count Vectorization - Unigram and Bigrams):
- Multinomial Naive Bayes
- Support Vector Machines
- Decision Tree
- From Tensorflow (Pre-trained Text Embedding Layer trained on English Google News 7B corpus):
- LSTM
- ANN
The models were developed using Google Colab (Link HERE).
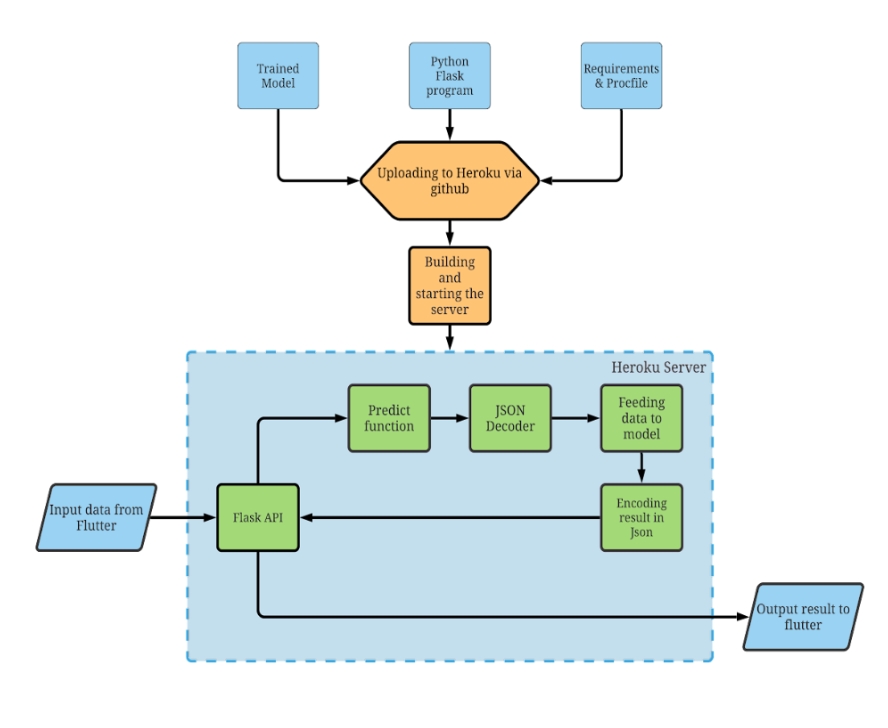
In order to perform the live testing of the models as well as deployment, an application was developed named ‘ARSA’ (Amazon Review Sentiment Analysis) (Code HERE). The flask program and ML models were uploaded to Heroku using Github REPO and the server was deployed. Within the server, the flask API waits for a POST request which will be sent by flutter when the user presses the ‘PREDICT’ button. This sends the data in json format to the API and also invokes the ‘/predict’ route where all the analysis takes place.
Application Screenshots:

Classification Report of all models:
| Model | Precision | Recall | F1-score | Support | |
|---|---|---|---|---|---|
| SVM | neg | 0.83 | 0.51 | 0.63 | 2446 |
| (uni-grams) | pos | 0.86 | 0.97 | 0.91 | 7554 |
| accuracy | 0.85 | 10000 | |||
| macro avg | 0.84 | 0.74 | 0.77 | 10000 | |
| weighted avg | 0.85 | 0.85 | 0.84 | 10000 | |
| SVM | neg | 0.83 | 0.53 | 0.65 | 2446 |
| (bi-grams) | pos | 0.86 | 0.97 | 0.91 | 7554 |
| accuracy | 0.86 | 10000 | |||
| macro avg | 0.85 | 0.75 | 0.78 | 10000 | |
| weighted avg | 0.86 | 0.86 | 0.85 | 10000 | |
| DT | neg | 0.56 | 0.54 | 0.55 | 2446 |
| (uni-grams) | pos | 0.85 | 0.86 | 0.86 | 7554 |
| accuracy | 0.78 | 10000 | |||
| macro avg | 0.7 | 0.7 | 0.7 | 10000 | |
| weighted avg | 0.78 | 0.78 | 0.78 | 10000 | |
| DT | neg | 0.56 | 0.54 | 0.55 | 2446 |
| (bi-grams) | pos | 0.85 | 0.86 | 0.86 | 7554 |
| accuracy | 0.79 | 10000 | |||
| macro avg | 0.71 | 0.7 | 0.7 | 10000 | |
| weighted avg | 0.78 | 0.79 | 0.78 | 10000 | |
| MNB | neg | 0.7 | 0.66 | 0.68 | 2352 |
| (uni-grams) | pos | 0.9 | 0.91 | 0.9 | 7648 |
| accuracy | 0.85 | 10000 | |||
| macro avg | 0.8 | 0.79 | 0.79 | 10000 | |
| weighted avg | 0.85 | 0.85 | 0.85 | 10000 | |
| MNB | neg | 0.68 | 0.73 | 0.7 | 2352 |
| (bi-grams) | pos | 0.9 | 0.91 | 0.9 | 7648 |
| accuracy | 0.85 | 10000 | |||
| macro avg | 0.79 | 0.81 | 0.8 | 10000 | |
| weighted avg | 0.86 | 0.85 | 0.85 | 10000 | |
| Neural Network | neg | 0.73 | 0.63 | 0.68 | 1276 |
| pos | 0.88 | 0.92 | 0.9 | 3724 | |
| accuracy | 0.85 | 5000 | |||
| macro avg | 0.8 | 0.78 | 0.79 | 5000 | |
| weighted avg | 0.84 | 0.85 | 0.84 | 5000 | |
| LSTM | neg | 0.66 | 0.75 | 0.7 | 1276 |
| pos | 0.91 | 0.87 | 0.89 | 3724 | |
| accuracy | 0.84 | 5000 | |||
| macro avg | 0.78 | 0.81 | 0.79 | 5000 | |
| weighted avg | 0.85 | 0.84 | 0.84 | 5000 |
It was observed that DT has the lowest scores (0.78) while the rest of the models had a similar accuracy (0.86 - 0.87). Also, it can be seen that the neural network models appear to have similar accuracy (0.85) as that of the simpler ML counterparts however, it must be noted that this accuracy was achieved with half the data than that feeded to ML models. As evident,, the neural network models outperform the ML models. However, the Neural Network models are comparatively heavier to deploy than ML models owing to the fact that they require higher computational power as well as memory space.