Classification of ISL using Pose and Object Detection based Techniques
According to the 2018-19 Annual report by the Indian Sign Language Research and Training Centre (ISLRTC), there are only 325 certified Sign language interpreters in India. This number is far lesser than required for translating the current 50,71,007 hearing-impaired and 19,98,535 speech-impaired persons in India (Census 2011).
Many times, the organizations required students and employees to work from home due to pandemics. This also helps organizations save money on various expenditures and is more time-efficient. This change has affected the deaf and hard-of-hearing students and job candidates negatively as, when hiring the candidate requires good internet connection and pin-drop silence at home but for hiring hard-of-hearing job candidates additional requirements such as availability of an interpreter becomes an additional hurdle. Also, hard-of-hearing students face similar issues in online lectures.
Thus, we present two approaches for the classification of Indian Sign Language:
- Pose-based approach utilizes an LSTM model which takes the skeletal pose landmarks from Mediapipe for a sequence of frames as an input to infer and predict the action.
- Object detection-based approach utilizes a model built on Scaled-YOLOv4 architecture which performs a frame-by-frame inference
Pose-based Estimation using LSTM
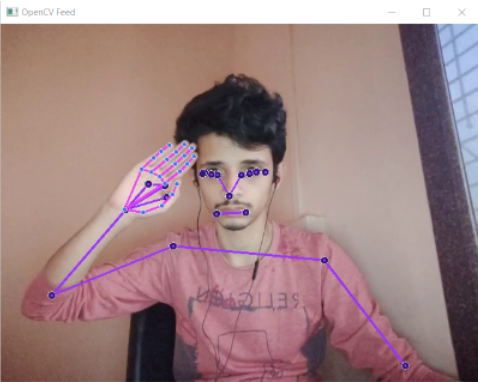
In this initial approach, the Sign-to-Text translation was performed by acquiring pose skeleton of the person from the input video which is achieved with the help of Holistic model from the Mediapipe Python library. This serves as a preprocessing step for the input is passed to the actual LSTM Model which then, provides the meaning of the Sign in the form of the classification result.
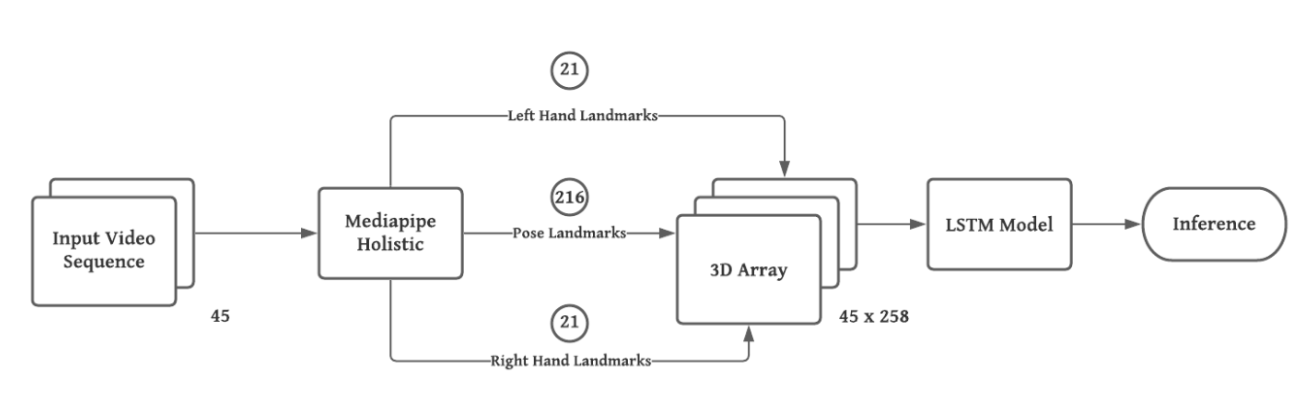
The input takes the form of a video or images. The input video frames would be given to the LSTM model once the landmarks have been extracted using the MP Holistic model. Finally, the LSTM model infers the input to provide the appropriate text for the given action.
Classification Report for LSTM
| Precision | Recall | F1-score | Support | |
|---|---|---|---|---|
| Hello | 1 | 1 | 1 | 17 |
| I | 1 | 0.91 | 0.95 | 11 |
| Thank You | 0.95 | 1 | 0.97 | 18 |
| Deaf | 0.94 | 1 | 0.97 | 15 |
| Work | 1 | 0.93 | 0.97 | 15 |
| Study | 1 | 0.95 | 0.97 | 20 |
| Good | 0.96 | 0.98 | 0.97 | 16 |
| Bad | 1 | 1 | 0.95 | 16 |
| accuracy | 0.98 | 128 | ||
| macro avg | 0.98 | 0.98 | 0.98 | 128 |
| weighted avg | 0.98 | 97 | 0.97 | 128 |
Confusion Matrix for LSTM
| Classes | True Positive | False Positive | True Negative | False Negative |
|---|---|---|---|---|
| Hello | 111 | 0 | 17 | 0 |
| I | 117 | 0 | 10 | 1 |
| Thank You | 109 | 1 | 18 | 0 |
| Deaf | 112 | 1 | 15 | 0 |
| Work | 113 | 0 | 14 | 1 |
| Study | 108 | 0 | 20 | 0 |
| Good | 112 | 0 | 16 | 0 |
| Bad | 112 | 0 | 15 | 1 |
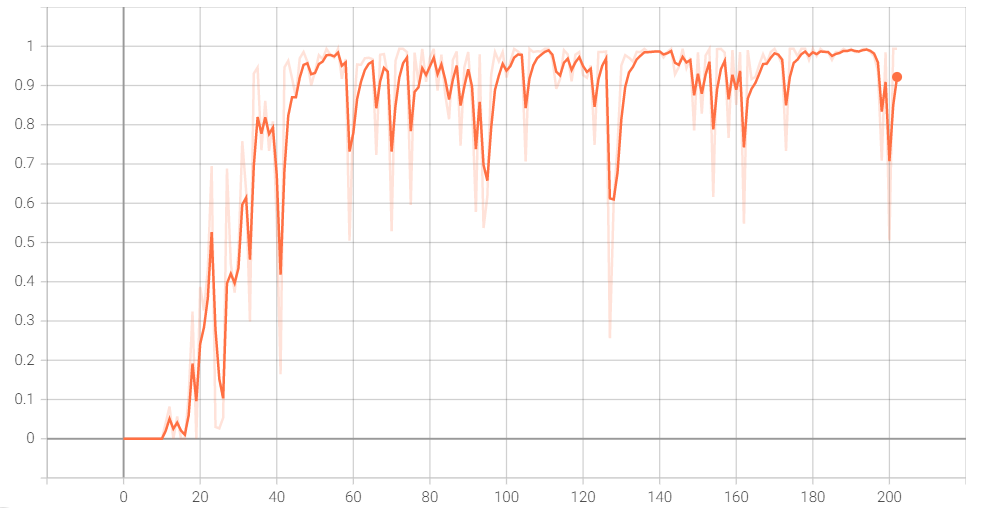
Accuracy Graph for LSTM
Object detection-based Classification using Scaled YOLO-v4
The initial approach, i.e the skeleton approach has a set of drawbacks when it comes to real-time deployment of models in a dynamic environment. The performance of the LSTM model developed for pose-based approach dwindled exponentially with increase in classes. Thus, with an imminent need for a newer approach, the idea of treating the hand-signs as an object was brought up. Finally, YOLO was utilized for the detection of these hand-sign objects.
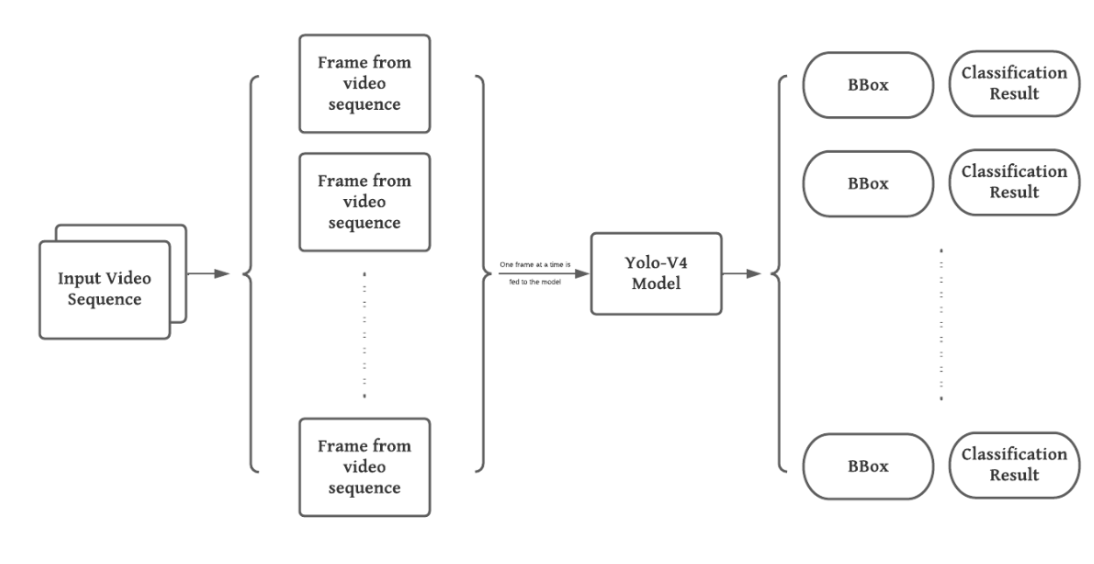
The input takes the form of a video or images. The input video frames would be given to the YOLO model once the image frame has been grayscale and then, output shall be generated for each in the form of bounding box coordinates and a class result.

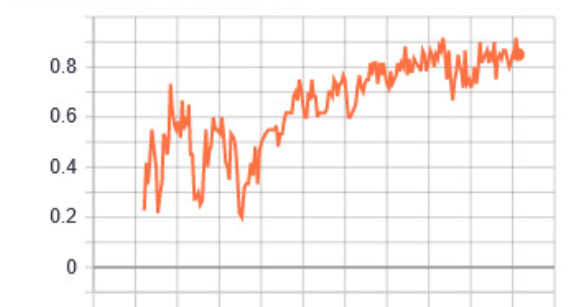
Mean Average Precision (0.5:0.95) Graph for Scaled-YOLOv4
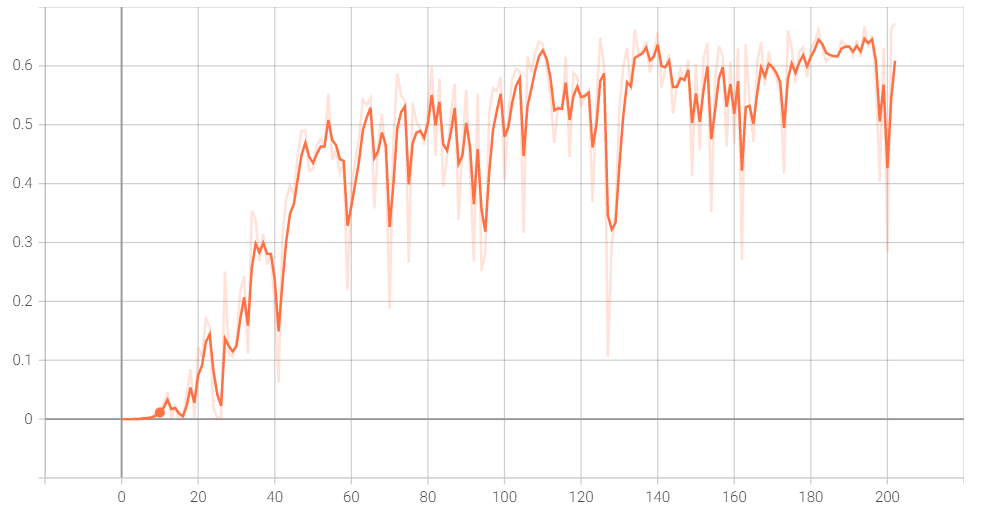
Precision for Scaled-YOLOv4
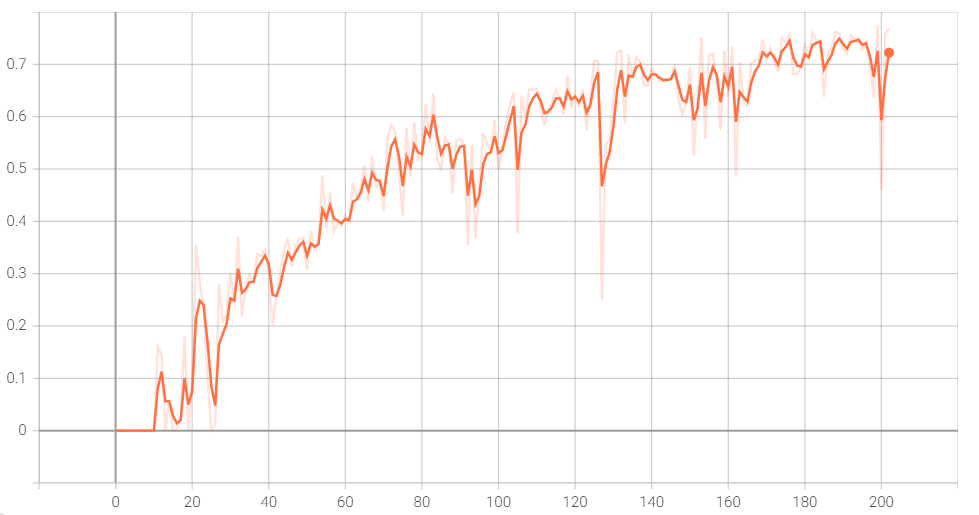
Recall for Scaled-YOLOv4